 具体到上一篇文章的环境下,由于原来的查询使用了like,所以优化器默认给的是loop join,这个IO的消耗是非常大的。 问题就变成了如何让查询利用上hash或者merge。改变一下语句,可以成为等号的连接查询,所以这样就可以利用上了hash join 欢迎大家一起来分析分析,并提供更好的查询方式。
具体到上一篇文章的环境下,由于原来的查询使用了like,所以优化器默认给的是loop join,这个IO的消耗是非常大的。 问题就变成了如何让查询利用上hash或者merge。改变一下语句,可以成为等号的连接查询,所以这样就可以利用上了hash join 欢迎大家一起来分析分析,并提供更好的查询方式。 关于上一个sql优化测试的部分知识
本文共 827 字,大约阅读时间需要 2 分钟。
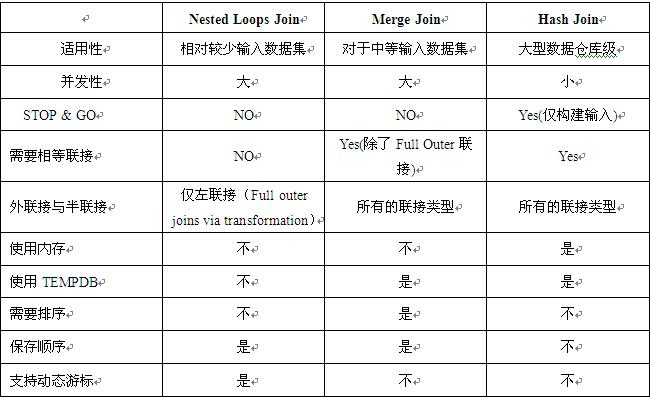
在上一个sql大牛提出的小测试中,优化的就是如何改变查询,来选择合适的连接方式。 mssql的连接方式有三种: hash join merge join loop join hash连接的的话,是将相连的2个表的连接字段都hash化,然后再查找,这样的好处在于如果你的连接字段是字符串类型,甚至是varchar(max)类型,那可想而知,如果一个一个对比,要花费多少时间对比。如果经过hash后,对比的数据量就明显减少,而且是对比值类型,对比数据非常快。但他也有不好的一面:经过hash后,就不能使用这样的连接符:< > like。因为hash后还怎能做相似或大小对比呢?只能是相等的对比(这种相等对比也存在小概率的原文不相等,但是hash数值相等,这种几率建立在hash算法的基础上)。而且hash适合于在连接字段没有索引的情况下,速度很快。hash最适合的场景是超大数据量。不过要将数据进行hash,是比较耗费数据库服务器的CPU资源的。 merge join 最适合的场景是表数据量相差不多的情况,两表数据进行归并。他的限制就是两表连接字段要进行排序,如果连接字段没有排序,那就会在执行计划里执行排序。 loop join 叫做嵌套循环查询,他最适合的场景是两表字段均有索引,而且最好是聚集索引(免去书签查找),这样IO更少。loop 是将小表做为外表来循环内表的每一行。在表小数据量的时候是不错选择。 具体要选用哪中连接方式,是需要综合各方面的考虑,不是光看一个方面就行的。这里,我找到一个图,连接方式的各种对比,讲的不错,贴上来跟大家共享: 具体到上一篇文章的环境下,由于原来的查询使用了like,所以优化器默认给的是loop join,这个IO的消耗是非常大的。 问题就变成了如何让查询利用上hash或者merge。改变一下语句,可以成为等号的连接查询,所以这样就可以利用上了hash join 欢迎大家一起来分析分析,并提供更好的查询方式。
具体到上一篇文章的环境下,由于原来的查询使用了like,所以优化器默认给的是loop join,这个IO的消耗是非常大的。 问题就变成了如何让查询利用上hash或者merge。改变一下语句,可以成为等号的连接查询,所以这样就可以利用上了hash join 欢迎大家一起来分析分析,并提供更好的查询方式。 转载地址:http://yxxgx.baihongyu.com/
你可能感兴趣的文章
统计单词个数
查看>>
Vue.js 第二天: 组件
查看>>
Django - Celery异步任务队列
查看>>
Android自定义View全解
查看>>
<HTTP权威指南>记录 ---- HTTP连接管理
查看>>
关于oss上传文件的封装函数
查看>>
一步一步学习SignalR进行实时通信_8_案例2
查看>>
windows环境利用hexo+github搭建个人博客
查看>>
小猿圈之浅析Java面试需要注意的方面?
查看>>
Prometheus学习系列(十四)之配置规则
查看>>
Humble Numbers
查看>>
SpringCloud(六):Zuul的多个使用场景
查看>>
用css怎么制作下拉列表
查看>>
从零开始搭建Android组件化框架
查看>>
day20 异常处理和约束
查看>>
ios观察者模式和通知中心
查看>>
struts1.2里的ActionMessages的使用
查看>>
OWL本体语言
查看>>
HDU1430 BFS + 打表 + 康托展开
查看>>
子网、超网和无类域间路由
查看>>